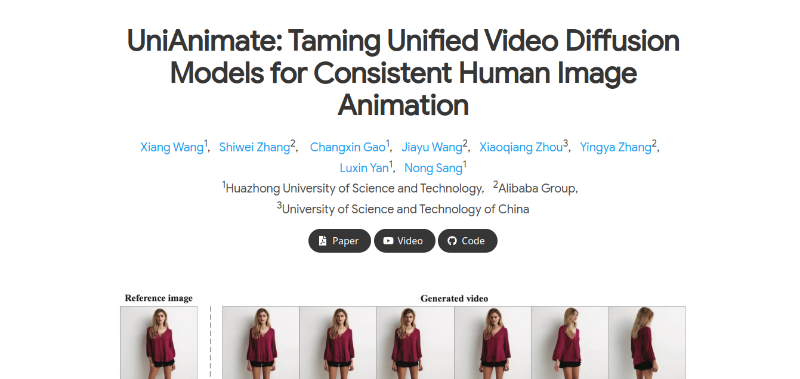
It discusses two limitations of existing techniques: needing a reference model and short video lengths. The proposed UniAnimate framework addresses these limitations. Overcomes limitations: It can generate human animation videos without needing a reference model and can produce longer videos than previous methods. Unified video diffusion model: UniAnimate combines reference images, posture guidance, and noise video into a single feature space, resulting in reduced complexity and improved temporal coherence. Long video generation: It utilizes a unified noise input that allows for random noise or conditioned inputs on the first frame, enabling long video generation. State space model: UniAnimate uses a state space model to replace the temporal Transformer for efficiency in long sequences. High-quality videos: The paper shows that UniAnimate generates higher quality videos than other methods.